Business Problem:
Coronavirus disease 2019 is a contagious disease caused by severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2). The disease has since spread worldwide, leading to an ongoing pandemic. Symptoms of COVID‑19 are variable, but often include fever, cough, headache, fatigue, breathing difficulties, and loss of smell and taste. Symptoms may begin one to fourteen days after exposure to the virus.
Background / History:
COVID‑19 transmits when people breathe in air contaminated by droplets and small airborne particles containing the virus. The risk of breathing these in is highest when people are near, but they can be inhaled over longer distances, particularly indoors. Transmission can also occur if splashed or sprayed with contaminated fluids in the eyes, nose, or mouth, and, rarely, via contaminated surfaces. People remain contagious for up to 20 days and can spread the virus even if they do not develop symptoms. This project proposal mainly aims at exploring COVID-19 through data analysis and projections.
Data Explanation:
The datasets are fetched from several websites which are mentioned as follows:
- John Hopins University – CSSEGISandData/COVID-19: Novel Coronavirus (COVID-19) Cases, provided by JHU CSSE (github.com).
- Apple mobility – COVID‑19 – Mobility Trends Reports – Apple
- World Health Organization – Coronavirus disease (COVID-19) (who.int)
- CDC – Coronavirus Disease 2019 (COVID-19) | CDC
After combining all data from various data sources, the dataset will have the following columns:
- State – State name.
- Country – Country name.
- Last Update – Last updated date of the data.
- Latitude – Latitude of the state.
- Longitude – Longitude of the state.
- Confirmed cases – Number cases confirmed at present.
- Deaths – Number of deaths happened so far.
- Recovered – Number of cases recovered.
- Active cases – Number of present active cases.
Methods:
This project concentrates more on visualization. So, I’m planning to use the seaborn library for all the visualization. Seaborn is a library for making statistical graphics in Python. It builds on top of matplotlib and integrates closely with pandas data structures. Seaborn helps you explore and understand your data. Its plotting functions operate on data frames and arrays containing whole datasets and internally perform the necessary semantic mapping and statistical aggregation to produce informative plots. Its dataset-oriented, declarative API lets you focus on what the different elements of your plots mean, rather than on the details of how to draw them.
For the prediction, we can include Support Vector Machine, Polynomial Regression, and Bayesian Ridge regression. Support vector machines are a set of supervised learning methods used for classification, regression, and outliers detection. Polynomial regression, like linear regression, uses the relationship between the variables x and y to find the best way to draw a line through the data points.
Analysis:
The Covid-19 pandemic is the most important health disaster that has surrounded the world for the past two years. The dataset consists of weekly confirmed cases and weekly cumulative confirmed cases obtained from World Health Organization and other organizations. Then the distribution of the data was examined using the most up-to-date Covid-19 weekly case data and its parameters were obtained according to the statistical distributions.
Conclusion:
As of now, to conclude we haven’t changed any of the methods for the prediction. We will split the training dataset into train and test sets and we will use the train set to fit the model and generate a prediction for each element on the test set. Finally, we will track all observations in a list called history that is seeded with the training data and to which new observations are appended at each iteration.
Assumption:
Here we are going to implement various methods to build the model. But again, we are not sure that any new mutation in the virus can change drastically the situation which will make the predictions wrong. But, for this analysis, we are assuming that no more mutation will be there in the COVID virus. Apart from this assumption, there is no assumption made and the values which we are going to implement in this project are real-time values only.
Limitation:
As mentioned earlier, we don’t know the exact accuracy until we complete the coding part of this project. And there are some other factors like virus mutation, government actions like curfews, lockdown, travel ban, etc will affect the real-time data and the predictions which is not considered here. So, probably the accuracy of the results may be less in this approach which can’t be mentioned now.
Challenges:
With the resurgence of machine learning and artificial intelligence, never has it been easier to implement predictive algorithms both new and old. With just a few lines of code, state-of-the-art models can be readily accessible at the fingertips of the budding data enthusiast, ready to conquer whatever insurmountable digital task may lay at hand. But a little bit of knowledge can be a dangerous thing. While much of machine learning can be attributed to statistics and programming what is equally important, but often skipped over in favor of instant gratification, is domain knowledge. There are a few Challenges in using the Bayesian Regression algorithm which is as follows:
- The inference of the model can be time-consuming.
- If there is a large amount of data available for our dataset, the Bayesian approach is not worth it and the regular frequentist approach does a more efficient job.
Future Uses:
COVID prediction aims to determine the number of persons affected in each country in the future. The accurate prediction of this scenario will lead to making decisions like lockdown, travel ban for each country to avoid the pandemic further worst. If the predictions came well with accuracy, we can implement it as a mobile app with a good User Interface for public use.
Recommendations:
As per websites like Kaggle and other data science websites, the recommended model for this project is Support Vector Machine, Polynomial Regression, and Bayesian Ridge regression. SVM is a supervised machine learning algorithm that can be used for both classification and regression challenges. In statistics, polynomial regression is a form of regression analysis in which the relationship between the independent variable x and the dependent variable y is modeled as an nth degree polynomial in x.
Implementation Plan:
We can use data from the above-mentioned sites to extract the data for the analysis. Then will create lots of visualizations to show the cases for each country. Then we will implement Support Vector Machine, Polynomial Regression, and Bayesian Ridge regression for the prediction. Based on the model accuracy we will conclude which model will be suited for predicting the COVID -19 cases and we can publish the results somewhere on the server.
Ethical Assessment:
In this project, we are going to use the data which is available for public use from websites like apple mobility, John Hoppins University, World Health Organization, etc. So, there are no ethical issues in handling data. But the ethical issue might raise when we release the results of this project because it’s experimental and we don’t know exactly how the model will behave for future predictions. So, there are some potential threats that the result may mislead the people and government of each country in the world. Thus, to avoid this kind of issue, we need to test the model thoroughly with all possible parameters.
Data visualization:
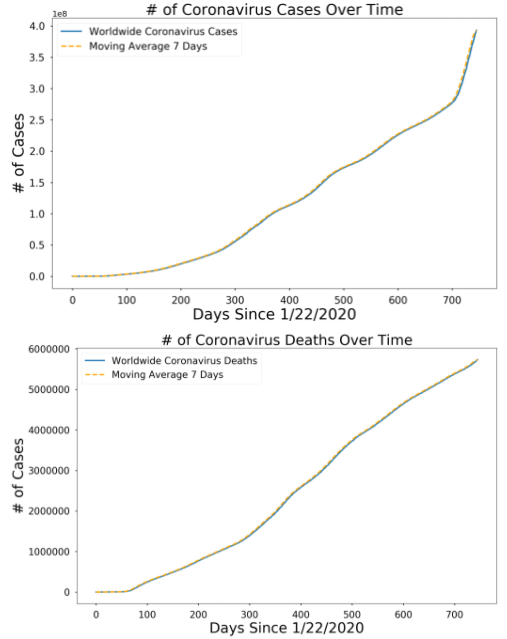
Corona cases and death over a period of time:
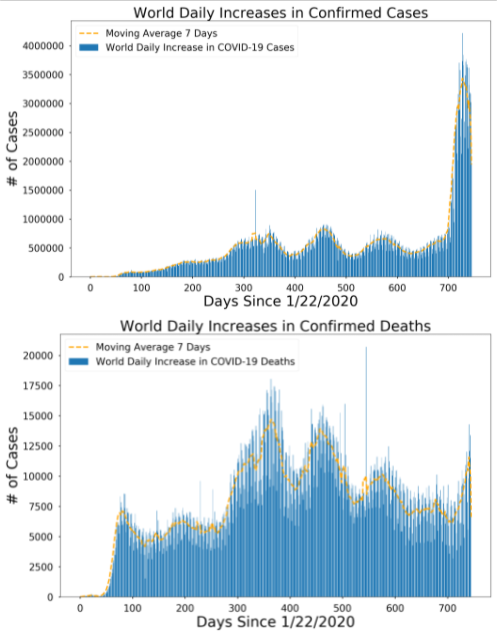
World daily increases in cases and death:
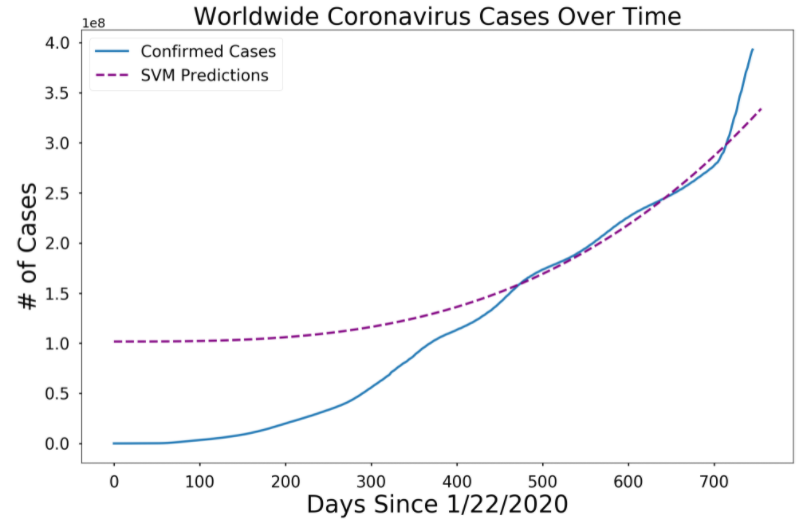
Prediction for Confirmed cases:
SVM:
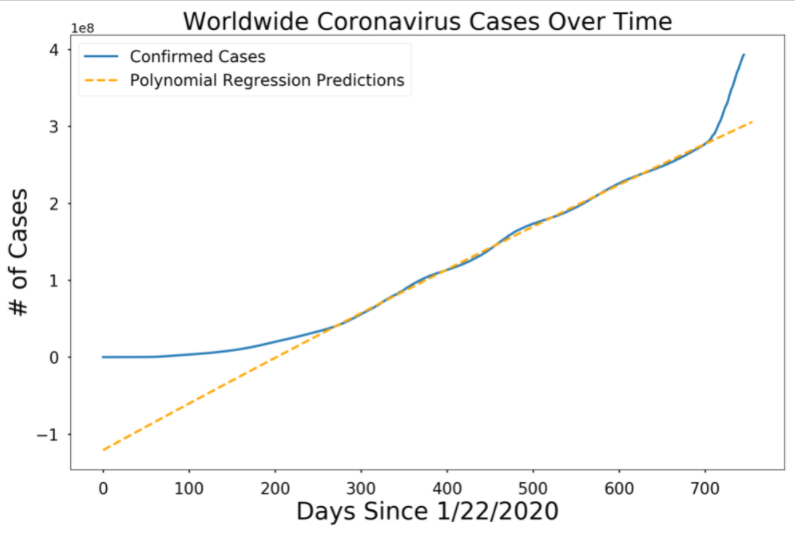
Polynomial regression prediction:
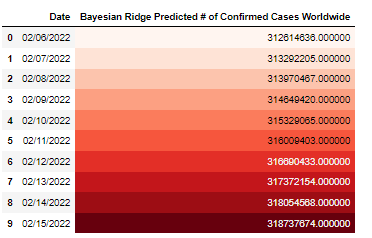
Bayesian Ridge Regression Predictions:

For the next 10 days:
SVM:
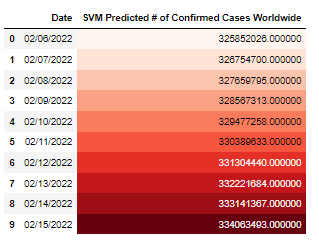
Polynomial Prediction:

Bayesian Ridge Prediction:
Github link – vasanthkalai/Covid-19Prediction (github.com)